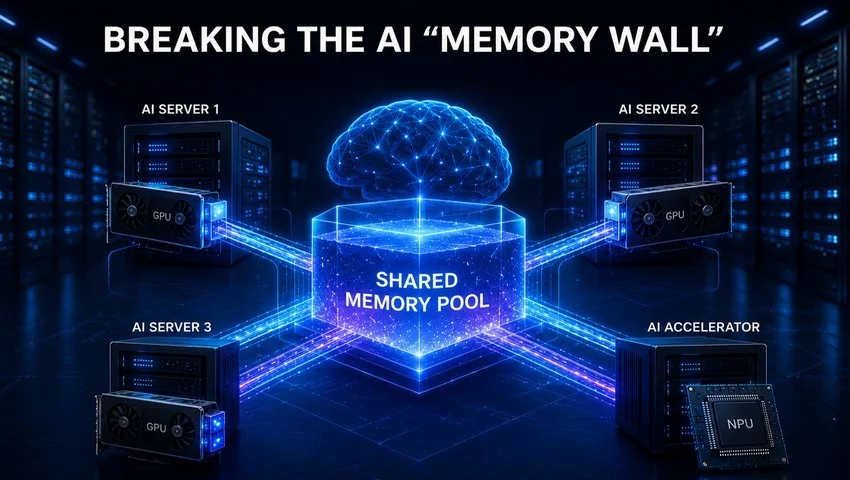
As artificial intelligence models continue to grow in size and complexity, one major challenge has become increasingly difficult to ignore: memory limitations. Even as GPUs become faster and more powerful, large-scale AI systems often hit what researchers call the “memory wall” – a bottleneck where insufficient memory capacity sharply reduces computational efficiency.
Now, researchers in South Korea have developed a promising solution.
The Electronics and Telecommunications Research Institute (ETRI) has presented OmniXtend, a memory expansion technology based on Ethernet. The breakthrough aims to overcome memory shortages in large-scale AI training environments and could significantly improve the scalability, cost-efficiency, and performance of future AI infrastructure.
The rapid rise of large language models (LLMs), generative AI, and high-performance computing workloads has dramatically increased memory demands. Traditional server architectures tightly couple memory to individual devices, creating severe scalability limitations.
OmniXtend introduces a fundamentally different approach. Instead of relying solely on locally attached memory, it uses standard Ethernet networks as a memory interconnect fabric. This enables memory resources to be pooled and shared dynamically across servers and accelerators, creating a unified, large-scale “memory pool” that can be accessed in real time.
In practical terms, distributed memory resources across an entire network can now function as one coherent, scalable system.
Conventional high-performance computing systems typically rely on high-speed serial interfaces such as PCIe. While effective for smaller setups, these architectures have limitations in scalability, connectivity distance, and deployment flexibility.
In contrast, OmniXtend leverages existing Ethernet infrastructure and standard Ethernet switches to aggregate multiple physically distributed devices into a shared-memory environment.
Key advantages include:
- Reduced data movement latency during AI training
- Expanded memory capacity without replacing existing servers
- Lower deployment and operational costs for data centers
- Improved scalability for hyperscale AI systems
By minimizing memory-related bottlenecks, the technology helps AI workloads maintain higher performance levels under demanding conditions.
To validate the architecture, ETRI developed several core enabling technologies, including:
- An Field-Programmable Gate Array (FPGA)-based memory expansion node
- An Ethernet-based memory transfer engine
- A scalable shared-memory management system
The team successfully demonstrated multiple devices operating in an Ethernet environment while accessing shared memory resources in real time.
In tests using large language model workloads, researchers observed that LLM inference performance degraded significantly when memory was insufficient. However, when Ethernet-based memory expansion was enabled, performance more than doubled. According to ETRI, this shows that shared-memory architectures can sustain processing performance comparable to systems with locally sufficient memory.
ETRI plans to commercialize OmniXtend through partnerships with data center hardware and software companies. Potential applications include AI training and inference servers, memory expansion devices, and high-performance network switches.The institute also intends to extend the technology to high-reliability embedded systems, such as automotive platforms and maritime applications.